








카카오는 5월 1일, 자사의 통합 멀티모달 언어모델 ‘Kanana-o’를 공개하며, 해당 모델이 텍스트, 음성, 이미지 데이터를 동시에 처리할 수 있는 능력을 자랑한다고 밝혔다. 이는 카카오가 국내 최초로 선보인 기술로, 다양한 형태의 데이터를 이해하고 자연스럽게 응답할 수 있는 차세대 인공지능 모델이다.
‘Kanana-o’는 텍스트와 음성, 이미지를 동시에 이해하고 처리하는 기술로, 텍스트 입력뿐만 아니라 음성이나 이미지를 포함한 복합적인 질문에도 적절한 응답을 제공한다. 카카오는 모델 병합 기술을 활용해 이미지 처리에 특화된 ‘Kanana-v’와 음성 이해 및 생성에 특화된 ‘Kanana-a’를 통합, 효율적인 개발을 완료했다. 이를 통해 시각, 청각, 텍스트를 동시에 학습하고 처리할 수 있는 모델이 구현됐다.
특히, ‘Kanana-o’는 음성 감정 인식 기술을 통해 사용자 의도를 정확히 파악하고, 억양이나 목소리 떨림 등 비언어적 신호를 분석해 자연스러운 음성으로 응답한다. 또한, 한국어 특유의 발화 구조와 방언을 정확히 반영해, 제주도나 경상도 방언도 표준어로 변환할 수 있는 능력을 보유했다. 이 모델은 스트리밍 방식으로 음성을 합성해 긴 대기 없이 즉각적인 응답을 제공하는 강점도 가지고 있다.
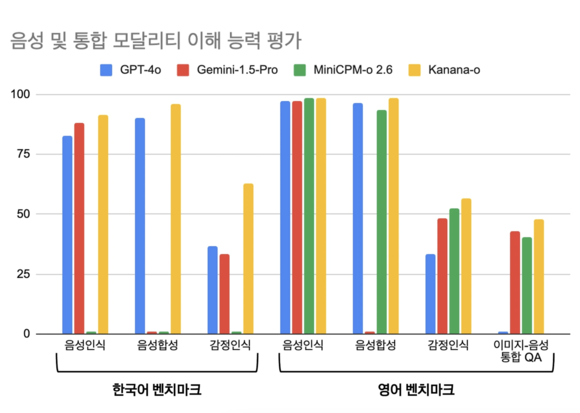
카카오는 이 모델을 통해 글로벌 최상위 모델들과 경쟁력 있는 성능을 기록했다. 특히 한국어 벤치마크에서 우위를 보였으며, 감정 인식 능력에서도 눈에 띄는 성과를 거두었다. 이미지와 음성을 통합적으로 이해하는 ‘이미지-음성 QA’ 태스크에서도 탁월한 성능을 보여, 통합 멀티모달 언어모델로서의 가능성을 확립했다.
향후 카카오는 ‘Kanana-o’를 다중 턴 대화 처리, 양방향 데이터 송수신 능력 강화, 안전성 확보 등의 목표로 연구 개발을 지속할 계획이다. 김병학 카나나 성과리더는 “Kanana 모델은 기존 텍스트 중심 AI를 넘어, 사람처럼 보고 듣고 말하며 공감하는 AI로 진화하고 있다”고 강조했다.
카카오는 지난해부터 ‘Kanana’ 모델의 라인업을 공개하며, 지속적인 연구 성과를 공유하고 있으며, AI 생태계 활성화를 위한 오픈소스 배포와 연구 논문 발표 등을 통해 국내 AI 발전에 기여하고 있다.









많이 읽은 기사










(03781) 서울시 서대문구 연희로 52-20 CNB빌딩 TEL:02-396-3733 FAX:02-396-7330
정기간행물 등록번호:서울다07522(등록일:2006.10.24), 인터넷신문등록번호:서울아04864(등록일:2017.12.06)
문화경제 발행인/편집인: 주금옥, 편집국장: 정의식, 청소년보호책임자: 류창림
대표메일 : cnbnews@cnbnews.com [이메일주소 무단수집 거부]